
주제
- 최대 절전 모드 및 JDBC에 배치 삽입/업데이트 구성 추가
- 배치로 처리할 때 성능 향상을 경험하십시오.
1. 일괄 삽입/업데이트 알아보기
1.1 일괄 삽입/업데이트 란?
INSERT INTO USER (ID, USER_NAME, AGE)
VALUES (1, '춘식이', 19);
INSERT INTO USER (ID, USER_NAME, AGE)
VALUES (2, '라이언', 20);
INSERT INTO USER (ID, USER_NAME, AGE)
VALUES (3, '어피치', 21);
...
...많은 양의 데이터를 조작하기 위해서는 저장 또는 업데이트를 여러 번 수행해야 합니다.
저장할 데이터가 10,000개라면 1개의 데이터를 10,000번 저장하는 쿼리(로직)를 실행하는 것보다,


한 번에 10,000개의 데이터를 저장하면 오버헤드가 줄어듭니다.
위의 단일 Insert 문은 다음과 같이 바꿀 수 있습니다.
INSERT INTO USER (ID, USER_NAME, AGE)
VALUES
(1, '춘식이', 19),
(2, '라이언', 20),
(3, '어피치', 21)
...
...
(10000, '브라운', 20);
단일 삽입 문은 여러 데이터를 조작합니다.
2. JPA에 지원
2.1 Hibernate와 JDBC를 이용한 배치 구성
2.1.1 하이버네이트와 JDBC란?
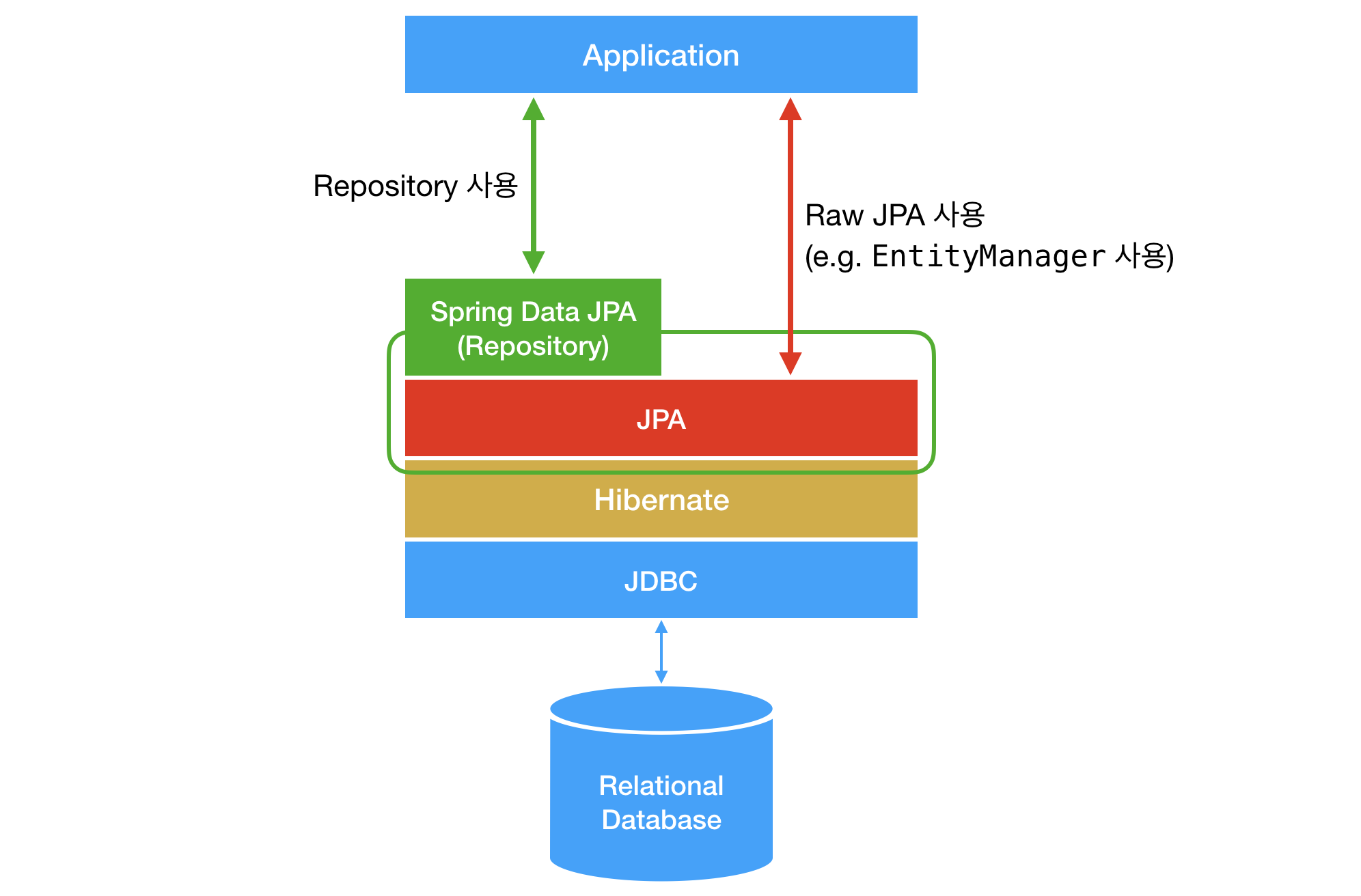
1) 최대 절전 모드
Hibernate는 JPA(Java Persistence API)의 대표적인 구현입니다.
우리가 사용하는 JPA라는 ORM 기술을 사용하기 위해 만든 프레임워크라고 생각하시면 됩니다.
Hibernate 설정에 따라 생성된 Entity는 DB 테이블로 생성되며, Application 단계에서 작성된 로직은 SQL로 변환되어 실행된다.
2) JDBC
JDBC는 Java와 DB를 연결하기 위한 표준 API인 Java DataBase Connectivity의 약자입니다.
Spring Boot에 의해 자동화된 수많은 구성 중에서 JDBC는 데이터베이스에 연결하는 데 사용됩니다.
JDBC를 사용하면 Java 애플리케이션이 DB와 통신할 수 있습니다.
JDBC를 통해 DB와 통신하는 과정은 간단하다.
- JDBC 드라이버 로드
- 연결 만들기
- Connection을 통해 DB와 통신
동일
하지만 Spring Boot에는 일반적으로 Connection Pool이라는 미리 만들어진 JDBC 연결을 저장하는 곳이 있고 DB에 연결할 때 이 연결 풀에서 차용한 연결을 사용하여 다시 돌려준다.
(이 때 사용한 HikariCP 커넥션 풀 라이브러리는)
2.1.2 적용 방법
1) 순수 JPA를 이용한 프로그래밍 방법
@Transactional(rollbackFor = Exception.class)
public void bulkInsertForIdEntity2(int totalCount, int batchSize) {
log.info("(bulkInsertForIdEntity2) bulk insert. total count is {}.", totalCount);
simpleIdRepository.deleteAll();
List<SimpleIdEntity> testData = createIdEntityList(totalCount);
int i = 0;
for (SimpleIdEntity entity : testData) {
em.persist(entity);
if(i % batchSize == 0) {
em.flush();
em.clear();
}
i++;
}
em.flush();
em.clear();
}
엔터티가 EntityManager에 지속되어 배치 크기만큼 누적되면 지속성을 플러시하고 지워서 지속성 컨텍스트에서 캐시된 엔터티를 제거합니다.
이것은 메모리 부족 문제를 방지합니다.
2) Hibernate와 JDBC 속성을 이용한 방법
MySql에서 사용할 수 있는 속성인 rewriteBatchedStatements 속성을 Hibernate에 적용합니다.
rewriteBatchedStatements 속성은 MySQL에서 사용할 수 있는 속성입니다. JDBC에서 배치 작업을 수행할 때 삽입, 업데이트, 삭제 쿼리를 다시 작성하여 성능을 향상시키는 기능입니다.
Hibernate에서 rewriteBatchedStatements 속성을 사용하려면 JDBC URL에 다음 매개 변수를 추가합니다.
jdbc:mysql://localhost:3306/mydb?rewriteBatchedStatements=true
다음으로 배치 크기에 도달할 때마다 플러시하기 위해 위의 For 문을 사용하는 것과 같이 Hibernate에서 설정할 수 있습니다.
# properties
spring.jpa.properties.hibernate.jdbc.batch_size=50
# yaml
spring:
jpa:
database: mysql
properties:
hibernate:
jdbc.batch_size: 100
order_inserts: true
order_updates: true
jdbc.batch_size : 한번에 연산할 데이터 개수
order_inserts: 수행할 쿼리의 순서를 지정하여 다른 insert 문이 작업을 방해하지 않도록 합니다.
order_updates: 다른 Update 문이 작업을 방해하지 않도록 실행할 쿼리의 순서를 정렬합니다.
2.2 주의사항
2.2.1 기본 키 생성 방법
기본 키 생성 방법이 Auto Increment인 경우 지원되지 않습니다.
2.2.2 데이터베이스 벤더의 지원
rewriteBatchedStatements 속성은 MySQL 전용 속성이므로 다른 데이터베이스를 사용할 때는 지원되지 않을 수 있습니다. 따라서 Hibernate에서 배치 작업을 수행할 때 데이터베이스 유형에 따라 최적화된 방법을 사용하는 것이 좋습니다.
2.2.3 적절한 배치 크기
배치 작업을 수행할 때 적절한 배치 크기는 여러 요인에 따라 달라질 수 있습니다. 일반적으로 다음 요소가 영향을 미칩니다.
1. 데이터베이스 유형
2. 사용 중인 JDBC 드라이버
3. 시스템 리소스(메모리, CPU, 디스크 I/O 등)
4. 네트워크 대역폭따라서 적절한 배치 크기를 결정하는 가장 좋은 방법은 위의 요소를 고려하여 성능 테스트를 수행하는 것입니다. 그러나 일반적으로 배치 크기는 20~50개가 적당하다고 알려져 있습니다.
배치 크기를 크게 설정하면 많은 메모리가 사용되며 OutOfMemoryError가 발생할 가능성이 높아집니다. 또한 배치 크기가 너무 크면 데이터베이스 서버에 부하가 가해져 전체 성능이 저하될 수 있습니다.
배치 크기를 작게 설정하면 여러 JDBC 호출이 발생하여 데이터베이스 서버에 부하를 줄 수 있습니다. 또한 JDBC 호출 횟수가 증가함에 따라 네트워크 대역폭이 소모되므로 데이터베이스 서버와 응용 서버 간의 네트워크 대역폭이 좁을 경우 성능이 저하될 수 있습니다.
따라서 적절한 배치 크기를 선택하기 위해서는 다양한 시스템 리소스와 데이터베이스 환경을 고려하여 실험적으로 다양한 배치 크기를 결정하는 것이 좋습니다.
ChatGPT의 답변
2.2.4 batch_size 속성이 기본적으로 false인 이유는 무엇입니까?
일괄 작업을 수행할 때 메모리 문제가 발생할 수 있으므로 False인 것 같습니다.
3. 다른 기술이 배치 작업을 처리하는 방법
Mybatis, QueryDSL, JOOQ 및 JPA는 모두 Java에서 SQL 쿼리를 작성하고 실행하기 위한 라이브러리이며 각 라이브러리는 배치 작업을 수행하는 방식이 약간씩 다릅니다. 다음은 각 라이브러리가 배치 작업을 수행하는 방식을 비교한 것입니다.
1) Mybatis: Mybatis는 SqlSessionTemplate을 사용하여 Batch 작업을 수행합니다. SqlSessionTemplate은 JDBC의 Batch 기능을 지원하며 SqlSessionTemplate의 배치 방식을 이용하여 Batch 작업을 수행할 수 있습니다.
2) QueryDSL: QueryDSL에서는 배치 쿼리를 작성하는 데 사용되는 JPQLBatchQuery를 사용하여 배치 작업을 수행할 수 있습니다. JPQLBatchQuery는 내부적으로 JDBC 일괄 처리 기능을 사용하므로 매우 빠른 성능을 제공합니다.
3) JOOQ: JOOQ는 BatchQuery 개체를 사용하여 일괄 작업을 수행합니다. BatchQuery 객체는 JOOQ에서 제공하는 DSL을 이용하여 생성되며, 이를 통해 Batch 쿼리를 생성할 수 있습니다.
4) JPA: JPA는 EntityManager의 플러시 방법을 사용하여 배치 작업을 수행합니다. flush 메서드는 지속성 컨텍스트에 축적된 변경 사항을 데이터베이스에 반영하는 역할을 합니다. 따라서 일괄 작업을 수행하려면 EntityManager를 명시적으로 호출하여 지속성 컨텍스트의 변경 사항을 반영해야 합니다.
위의 방법 중 JOOQ은 가장 빠른 성능을 보장하며, JOOQ은 내부적으로 JDBC의 일괄 처리 기능을 사용하므로 최적화된 성능을 제공합니다. 그러나 JOOQ는 SQL 쿼리를 생성하기 위해 많은 코드를 작성해야 하므로 개발자를 위한 학습 곡선을 가질 수 있습니다.
그 외 모든 라이브러리는 ORM(Object-Relational Mapping) 라이브러리로 SQL 쿼리 자동 생성 등의 편의성을 제공합니다. 그러나 ORM 라이브러리는 내부적으로 많은 코드를 실행하기 때문에 성능이 JOOQ보다 느릴 수 있습니다. 또한 ORM 라이브러리는 자동으로 SQL 쿼리를 생성하므로 개발자는 종종 SQL 쿼리를 작성할 필요가 없지만 ORM 라이브러리의 내부 작동 방식을 이해해야 합니다.
# 참조